Nachdem ich im ersten Teil dieser Artikelserie vorgestellt habe, wie Protokolle in Azure Sentinel aufgenommen werden können, werde ich nun folgende Themen erörtern:
- Entwicklung von Warnregeln zur Erkennung böswilligen Verhalten
- Erstellung automatisierter Reaktionsschritte auf Vorfälle, um bei der Untersuchung und Reaktion von Vorfällen zu helfen
- Definition von Zustandskontrollen, um sicherzustellen, dass alles wie erwartet funktioniert.

Entwickeln von Warnregeln
Sobald die Protokolle aufgenommen wurden, besteht der nächste Schritt darin, aus den Protokollen verdächtige oder böswillige Aktivitäten zu erkennen. Hier kommen Warn-Regeln (auch als Analytik-Regeln bezeichnet) ins Spiel.
Obwohl Microsoft einige Standard-Warnregeln zur Erkennung bekannter Malware oder anderer gängiger verdächtiger Aktivitäten zur Verfügung stellt, ist es trotzdem sehr wahrscheinlich, dass die Entwicklung eigener Regeln erforderlich ist. DieWarnregeln basieren auf Protokollabfragen, die mit der Kusto Query Language (KQL) definiert wurden.

Die Warnregeln funktionieren, indem sie die KQL-Abfrage in regelmässigen Abständen (Formular alle paar Minuten bis zu allen paar Tagen) ausführen und Warnungen generieren, wenn das definierte Kriterium erfüllt ist, z. B. wenn die Abfrage mindestens ein Ergebnis zurückgibt. Jede Warnung kann dann einen zu untersuchenden Vorfall generieren oder mit anderen ähnlichen Warnungen zu einem einzelnen Vorfall aggregiert werden. Dies ist besonders wichtig, da Sie nicht möchten, dass Ihre Analysten unabhängig voneinander mehrere Vorfälle untersuchen, die eigentlich identisch sind. Die Aggregation basiert auf Einheiten, bei denen es sich um IP-Adressen, Hostnamen, Benutzer oder URLs handelt. Diese Einheiten sind als Teil der KQL-Abfrage definiert und entsprechen den verschiedenen Knoten, die im Untersuchungsbereich angezeigt werden.
Abgesehen von den allgemeinen Einstellungen, wie dem Schweregrad des Vorfalls, können die Alarmregeln den MITRE ATT&CK®-Taktiken zugeordnet werden. Diese können dann leicht verwendet werden, um ein Verständnis dafür zu erhalten, was Ihre ATT&CK-Abdeckung ist und was in Bezug auf die Erkennung von Angreifer-Aktionen verbessert werden kann.
Erstellen automatisierter Antwortschritte
Aus technischer Sicht ist die grösste Komponente im Incident Response-Prozesses die automatisierte Reaktion, die mit Logic Apps (auch als Sentinel-Playbooks bezeichnet) durchgeführt wird.
Automatisierte Reaktionen auf Vorfälle können direkt eingerichtet werden, wenn die Warnregeln definiert werden. Ein oder mehrere Playbooks können erstellt und mit der Regel verknüpft werden. Wenn eine Warnung ausgelöst und ein Vorfall erstellt wird, werden die verknüpften Logik-Apps automatisch ausgeführt. Dies kann z. B. verwendet werden, um Benachrichtigungen an ein Analystenteam zu senden, wenn ein kritischer Vorfall vorrangig untersucht werden muss.
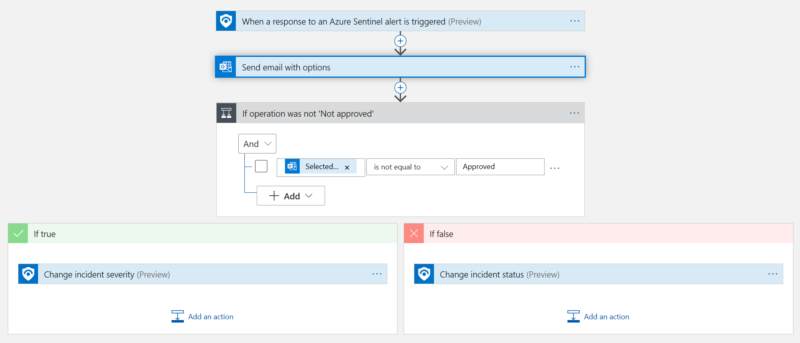
Abbildung 1. Logik App sendet eine Genehmigungs-E-Mail, wenn eine Warnung ausgelöst wird
Obwohl diese Arten der automatisierten Antwort nützlich sein können, möchten Sie nicht unbedingt Benachrichtigungen für jeden neu erstellten Vorfall zusenden. In diesen Fällen kann die Automatisierung zu einem späteren Zeitpunkt des Untersuchungsprozesses erfolgen, z. B. wenn einem Analytiker ein Vorfall zugeordnet wird oder wenn der Schweregrad des Vorfalls erhöht wird.
Definieren von Zustandskontrollen
Übergreifend für alle anderen Komponenten stellen Zustandskontrollen sicher, dass es bei der Erkennung keine unterbrochenen Verbindungen gibt. Die besten Alarmierungsregeln und der beste Prozess zur Reaktion auf Vorfälle wären ziemlich nutzlos, wenn der Prozess zur Aufnahme von Protokollen nicht funktioniert und keine Protokolle empfangen werden. Deshalb ist es wichtig, sicherzustellen, dass alles ordnungsgemäss läuft und dass man benachrichtigt wird, wenn etwas kaputt ist.
Um dies zu erreichen, können Monitor-Alerts genutzt werden. Wie Sentinel kann auch Monitor als Überlagerung eines Log Analytics-Arbeitsbereichs gesehen werden, konzentriert sich aber eher auf die Verfügbarkeit und Leistung von Ressourcen als auf die Sicherheit.
Der Entwicklungsprozess für Monitorwarnungen ähnelt dem für Sentinel-Warnungen:
- Erstellen einer Warnung, die ausgelöst wird, wenn die definierten Kriterien erfüllt sind
- Definieren von automatisierten Benachrichtigungen für den Zeitpunkt, an dem eine Warnung ausgelöst wird
Bei Zustandsüberprüfungskontrollen werden bei den zugrunde liegenden Daten keine Sicherheitsprotokolle, sondern Ressourcenmetriken oder Aktivitätsprotokolle verwendet.
Eine wichtige Kontrolle, die Sie implementieren sollten, ist sicherzustellen, dass alle Logic Apps und Azure-Funktionen fehlerfrei laufen; dies kann über die Metriken für fehlgeschlagene Läufe erreicht werden. Bei der Verwendung virtueller Maschinen, kann es ebenfalls sinnvoll sein, sicherzustellen, dass die CPU- oder Speichernutzung nicht zu hoch ist. Dies wird gleichermassen über VM-Metriken erreicht.
Mithilfe von Aktivitätsprotokollen ist es möglich, Kontrollen dafür zu entwerfen, wann Azure-Ressourcen geändert oder gelöscht werden; dies ist besonders wichtig in einer Produktionsumgebung, in der Änderungen nicht aus heiterem Himmel erfolgen sollten. Bei genehmigten und getesteten Änderungen kann der Monitor-Alert dann vorübergehend unterdrückt werden (entweder global oder nur für eine Teilmenge von Ressourcen).
Benachrichtigungen per E-Mail oder SMS können direkt im Monitor eingerichtet werden, oder es werden Logic Apps verwendet, wie in unserem Fall, wo wir Benachrichtigungsnachrichten an unseren Team-Kanal senden.
Was kommt als nächstes?
Das Sammeln von Protokollen, das Erstellen von Warnmeldungen für böswillige Aktivitäten, das Definieren automatisierter Reaktionsschritte und das Sicherstellen, dass alles wie erwartet funktioniert; das sind einige der grundlegenden Schritte, die Sie durchlaufen müssen, um Cyber-Vorfälle zu erkennen und darauf zu reagieren.
Es gibt jedoch viel mehr, als man tun kann, um gut definierte und optimierte Erkennungs- und Reaktionsfähigkeiten zu haben.
Ein Aspekt, den wir derzeit mit unserem Kunden implementieren, ist die Versionskontrolle. Sentinel bietet keine Versionskontrollfunktionen, und obwohl Sie verfolgen können, wer für die Änderung verantwortlich ist, können Sie nicht zu einer früheren Version einer Analyseregel oder einer Logikanwendung zurückkehren, wenn eine Änderung einen Fehler verursacht.
Ein weiteres Thema, welches derzeit entwickelt wird, ist die Verbindung von Sentinel mit ServiceNow. Sentinel bietet zwar Untersuchungsmöglichkeiten, aber es fehlen noch immer die Möglichkeiten, für hochrangige Vorfallverwaltungs- und Verfolgungssysteme der Ticketing-Systeme.
Bleiben Sie auf dem Laufenden, wenn Sie mehr darüber erfahren möchten, wie wir bei Arco IT Sentinel einsetzen. Der nächste Artikel behandelt die operative Seite und stellt dar, wie Vorfälle untersucht werden.